By Meryl Alper
By default, synthetic speech has historically represented voices emanating from adult, white, male, and cisgender bodies. Machine-generated voices reflect the backgrounds of professionals in disciplines related to speech synthesis, such as engineering, as well as the commercial synthetic voice models that they designed and constructed in the late 20th century. The erasure of women, people of color, and gender nonconforming individuals from the social and technical construction of synthetic speech shapes the identities that computerized voices can potentially convey.
Take one of the world’s most pervasive speech synthesis systems: Apple’s built-in synthesizer MacinTalk and screen-reading technology VoiceOver. Apple is widely acclaimed for designing robust accessibility features into its operating systems (OS). One of these features is VoiceOver, “an alternative way of interacting with the Macintosh that […] generates spoken output” and “allows visually impaired users to use applications and macOS itself using only the keyboard.” There is a uniformity to the VoiceOver voices exemplified by the Female options that are labeled with mostly Anglo-origin names like “Agnes,” “Victoria,” and “Samantha,” which reinforces white supremacy. But Apple is not alone here. Microsoft’s artificially intelligent talking personal assistant Cortana (the company’s answer to Apple’s Siri) is named after a character from the Halo video game franchise for their Xbox console. Cortana is a thin, presumably cisgender, light-skinned, woman hologram.
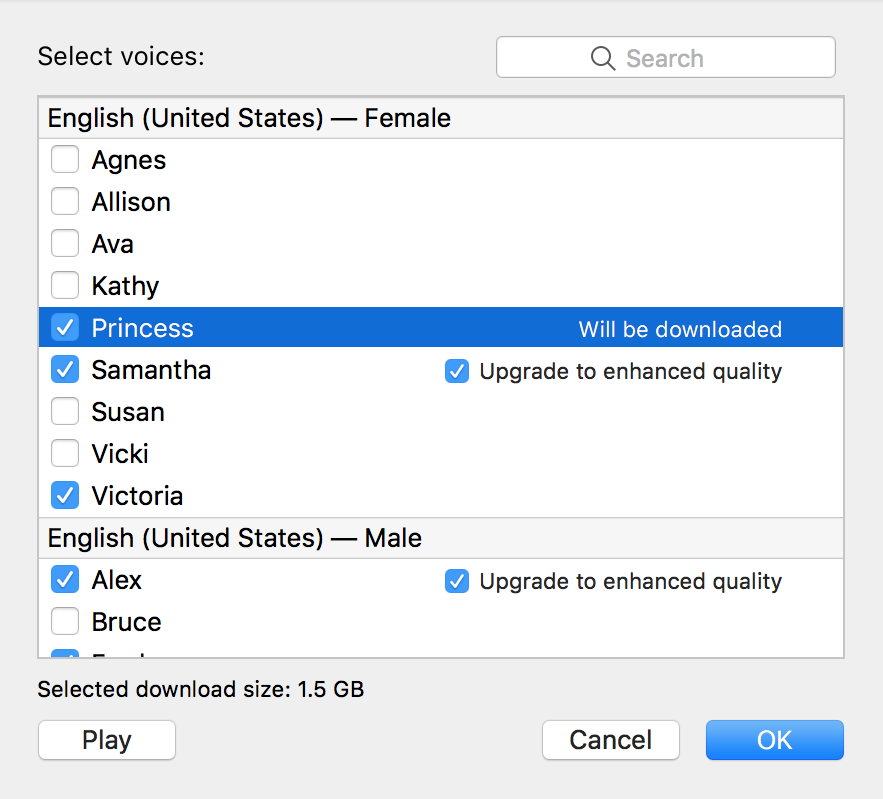
There is also a more limited range of VoiceOver voice output options in mobile iOS than Apple’s desktop macOS. One of the voice options included in macOS (but not iOS) under the “English (United States)—Female” category is “Princess.” Nothing is particularly regal about the voice of “Princess,” which has a tinny, underwater gurgle quality. “Princess,” as a label, signifies a young age range as opposed to an older queen. Apple’s VoiceOver categories also reinforce a gender binary; outside of Female and Male, the only other category is Novelty. Is anything that falls outside of those two genders considered a “novelty” voice de facto?
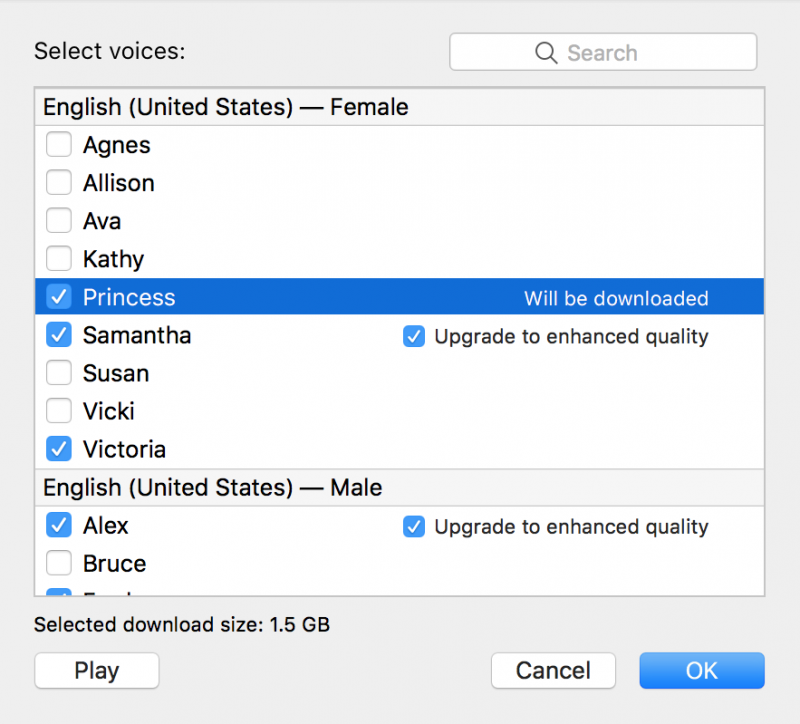
In its sample of synthetic speech, the Apple macOS VoiceOver’s “Princess” voice says, “When I grow up, I’m going to be a scientist.” Screenshot of Apple VoiceOver Utility settings by Meryl Alper.
Although having the only young girl option on VoiceOver be named “Princess” inherently enforces gender essentialism, particularly as there is no “Prince” option, “Princess” also interestingly challenges gender stereotypes. Apple provides samples of each voice in its customization options for system voices, and while one might expect it to say any number of cringe-worthy sample phrases, VoiceOver introduces “Princess” with “When I grow up, I’m going to be a scientist.” Creating a synthetic voice involves mimicking both the cultural (e.g., gender norm-based) and biological (e.g., sex-based) characteristics of a person’s voice, as well as imagining the content of their speech and the purpose of their speech acts. Princess exemplifies these multilayered characteristics of synthetic speech by sounding both sweet and subversive.
These choices for synthetic voices, or lack thereof, directly and indirectly impact disabled users in myriad ways. For an “accessibility” feature, VoiceOver’s Novelty category contains labels for voices that mock individuals with mental health challenges and draw upon gendered tropes of mental illness. Among the labels in the Novelty category is a voice named “Deranged” (which says in its sample, “I need to go on a really long vacation”) and another named “Hysterical” (which cries, “Please stop tickling me”).
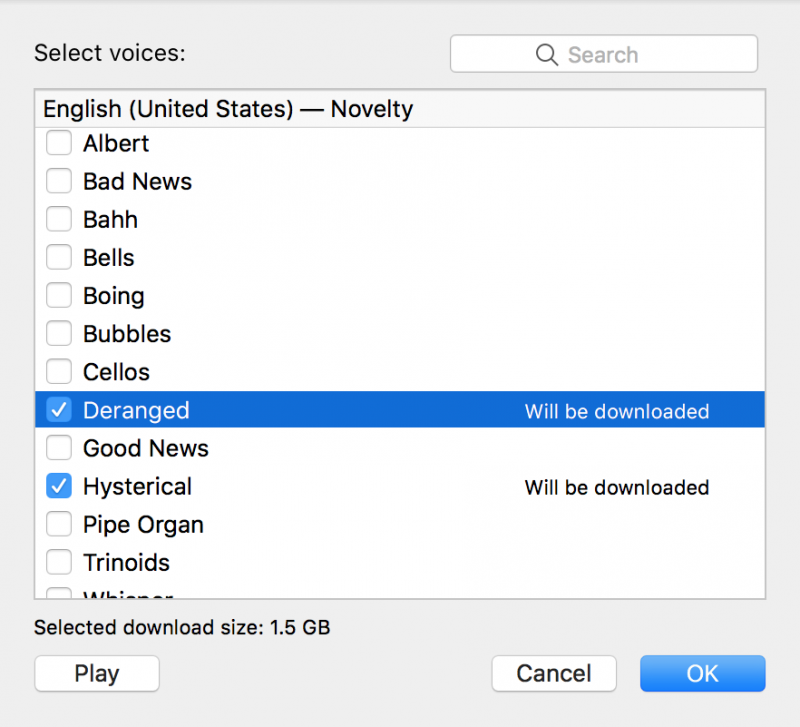
Apple macOS VoiceOver Novelty voice options include the ableist descriptors “Deranged” and “Hysterical.” Screenshot of Apple VoiceOver Utility settings by Meryl Alper.
Individuals with significant speech impairments (due to developmental or acquired language disorders such as apraxia or aphasia) who speak using synthetic voices face a double bind. When synthetic speech takes the form of “text-to-speech” (TTS), it vocalizes written content that hearing individuals can listen to. For instance, Siri can tell you where to find the nearest sushi restaurant without having to look it up online. This same technology can aid people who may or may not also have disabilities. A computer, for example, can read aloud for blind users the sushi menu from a webpage (as long as that menu is accessible to screen reading software).
With TTS, the text is written by one person and spoken by an inanimate object for a different person to hear. But what about non-speaking individuals with disabilities? Their use of synthetic voices might be more akin to “speaking-to-speech,” as the construction of an utterance, phrase, or sentence is context dependent. If we only focus on speaking individuals as the users of synthetic speech, then we miss out its applications to a full range of consumers and needs.
All of this matters because while synthetic speech is often assumed to be an “accessible” technology that enables agency and self-expression, it also simultaneously reproduces and amplifies power imbalances. For my book, Giving Voice: Mobile Communication, Disability, and Inequality, I conducted ethnographic fieldwork among young people with significant speech impairments and found that racial and gender power imbalances manifested in synthetic speech in various ways. It came through in how young women with speech disorders used and creatively misused their more limited range of synthetic voices to communicate, and in how the parents of young non-speaking white boys more often discussed the ease with which they selected a “natural” voice for their child to use.
Much work needs to be done to correct these imbalances. Companies like VocaliD are making strides to crowdsource vocal samples from a more diverse population to create customized synthetic voices beyond the generic few. In Giving Voice, I suggest that it’s only by “keeping voices attached to people” that we avoid abstracting notions of voice and automatically equating synthetic speech with agency and empowerment when used by people with speech disabilities. This conceptualization borrows from historian Katherine Ott’s challenge to scholars of technology and society to stop abstracting the idea of prosthetics from the lived realities of prosthetic users, and to instead “[keep] prosthesis attached to people.” Simply put, technology begets both pain and pleasure for those with disabilities.
Humans craft speech technology that other humans use to speak. Synthetic voice options for anyone except cis white men have historically been limited and complicated. Voice is material and embodied, and even more so in the form of synthetic speech. “Voicelessness” isn’t an individual biological trait; being silent or speechless is socially, culturally, and politically shaped. Understanding the gendered politics of speech synthesis through the lens of disability enables us to re-shape the agenda and priorities of speech synthesis and technologies. Speech synthesis should be intersectional and polyvocal, and voices should be engineered and designed by more than just able-bodied cisgender white men. People with disabilities can be agents of change for promoting a more ethical approach to conversational agents.
Further Reading
Alper, Meryl. Giving Voice: Mobile Communication, Disability, and Inequality. Cambridge, MA: MIT Press, 2017.
Mills, Mara. “Media and Prosthesis: The Vocoder, the Artificial Larynx, and the History of Signal Processing.” Qui Parle: Critical Humanities and Social Sciences 21, no. 1 (2012): 107–149.
Ott, Katherine. The Sum of Its Parts: An Introduction to Modern Histories of Prosthetics. In Artificial Parts, Practical Lives: Modern Histories of Prosthetics, ed. Katherine Ott, David Serlin, and Stephen Mihm, 1–42. New York: NYU Press, 2002.
Schiebinger, Londa, Ineke Klinge, Hee Young Paik, Inés Sánchez de Madariaga, Martina Schraudner, and Marcia Stefanick (Eds.). “Making Machines Talk: Formulating Research Questions.” Gendered Innovations in Science, Health & Medicine, Engineering, and Environment, https://genderedinnovations.stanford.edu/case-studies/machines.html, 2011-2017.
Dr. Meryl Alper is an Assistant Professor of Communication Studies at Northeastern University and a Faculty Associate at the Berkman Klein Center for Internet and Society at Harvard University. She studies the social implications of communication technologies, with a focus on youth and families, disability, and mobile media. Dr. Alper is the author of Digital Youth with Disabilities (MIT Press, 2014) and Giving Voice: Mobile Communication, Disability, and Inequality (MIT Press, 2017). She can be found on Twitter @merylalper and online at merylalper.com.